
Build-LLAMA2: Mini Llama2 Transformer Implementation & Weight-Space Ensemble Fine-Tuning
Date:
Deep Learning, Natural Language Processing, Transformer Architecture, LoRA, WiSE-FT
| 📄 Project Report (PDF) | 💻 GitHub Repository |
Introduction
This project involves building a mini Llama2-style transformer from scratch—including attention mechanisms, feed-forward layers, positional encoding, and complete training infrastructure—followed by implementing and evaluating Weight-Space Ensemble Fine-Tuning (WiSE-FT) to understand how weight interpolation can improve downstream task performance and model robustness.
The implementation follows the structure of Llama2 (Touvron et al., 2023), with careful reproduction of key architectural components and training behavior. The project results in a fully functional decoder-only transformer capable of text continuation, zero-shot classification, and downstream fine-tuning tasks.
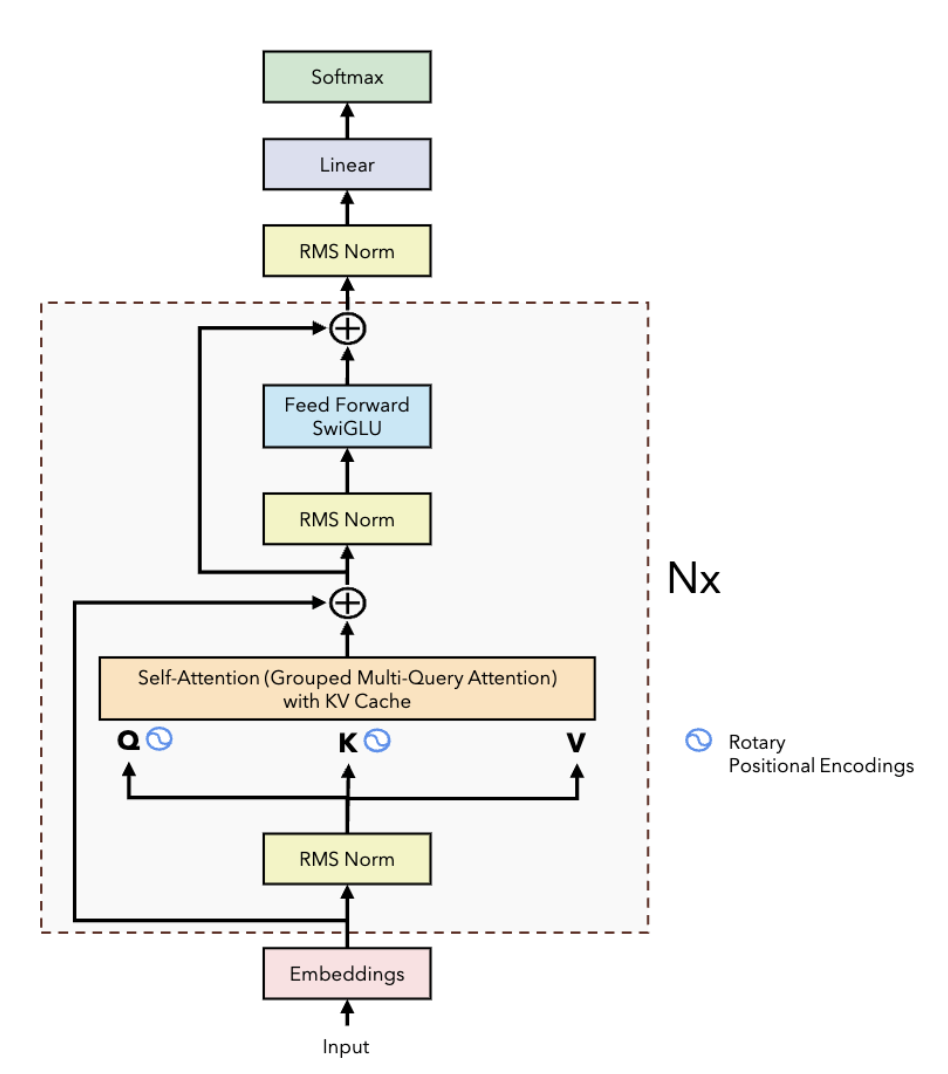 Figure 1: Llama2 Decoder-Only Transformer Architecture with GQA, RoPE, and SwiGLU
Figure 1: Llama2 Decoder-Only Transformer Architecture with GQA, RoPE, and SwiGLU
Architecture Implementation
Core Components
I implemented all major components of the Llama2 decoder architecture from scratch:
Attention Mechanism:
- Grouped Query Attention (GQA) - Memory-efficient attention with shared key-value heads
- Multi-head self-attention with causal masking
- Rotary Position Embeddings (RoPE) - Relative positional encoding
Feed-Forward Network:
- SwiGLU activation - Improved over standard ReLU/GELU
- Gated linear units for enhanced expressiveness
Normalization & Residuals:
- Pre-LayerNorm architecture - Stabilizes training
- Residual connections throughout all layers
Training Infrastructure:
- Custom training loop with AdamW optimizer
- Cosine learning rate schedule with warmup
Mixed precision training support (fp16/bf16)
Training Pipeline
Data Processing & Training Loop
- Implemented tokenization pipeline using Llama’s tokenizer
- Built end-to-end training infrastructure:
- Forward pass with efficient tensor operations
- Loss computation and backpropagation
- Gradient accumulation and clipping
- Checkpoint management
Supported Training Modes
- GPT-style Pretraining - Causal language modeling on large corpora
- Text Continuation - Autoregressive generation and perplexity evaluation
- Downstream Fine-tuning - Task-specific adaptation (classification, QA)
Parameter-Efficient Fine-Tuning (PEFT)
LoRA (Low-Rank Adaptation)
- Injected trainable low-rank matrices ($\Delta W = BA$) into attention projection layers
- Achieved strong adaptation with < 5% of parameters trainable
- Maintained base model weights frozen, enabling efficient multi-task deployment
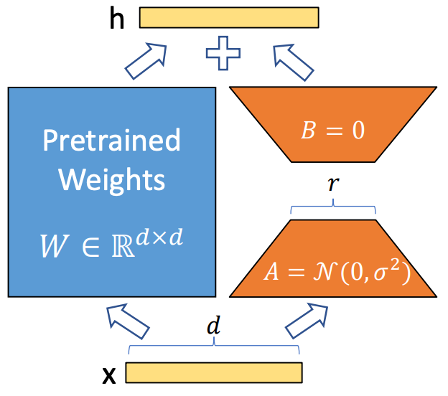 Figure 2: LoRA Overview
Figure 2: LoRA Overview
WiSE-FT (Weight-Space Ensemble Fine-Tuning)
Core Concept:
Instead of using only fine-tuned weights, interpolate between pretrained and fine-tuned weights:
where $\alpha \in [0, 1]$ is the interpolation coefficient.
Implementation:
- Explored interpolation coefficient $\alpha \in [0, 1]$ with grid search
- Evaluated on zero-shot classification and out-of-domain robustness
- Compared three strategies: Vanilla Fine-tuning vs LoRA vs WiSE-FT
Experimental Results
Tasks Evaluated
- Text Continuation Perplexity - Language modeling capability
- Zero-shot Classification - SST-2 (sentiment), AGNews (topic classification)
- Fine-tuning Performance - Comparing LoRA and WiSE-FT strategies
Key Findings
1. WiSE-FT Improves Robustness
- Demonstrated strong robustness on out-of-domain samples
- Interpolating with $\alpha \in [0.2, 0.4]$ gave best balance between in-domain and out-of-domain performance
- Avoided overfitting while maintaining task-specific improvements
2. LoRA Stabilizes Training
- Reduced parameter count by 95% while maintaining performance
- Improved training stability with fewer optimization steps
- Enabled efficient multi-task adaptation
3. Architecture Validation
- Base model reproduced expected loss curves for small-scale Llama architecture
- Achieved competitive perplexity on validation sets
Confirmed correct implementation of all architectural components
Repository Contents
The complete implementation is available on GitHub:
model.py- Full transformer implementationrope.py- Rotary Position Embeddingstrain.py- Training and evaluation scriptslora.py- LoRA implementationwise_ft.py- WiSE-FT weight interpolation- Configuration files and example notebooks
Discussion
This project demonstrates several important insights:
From-Scratch Implementation Value:
Building transformers from scratch provides deep understanding of:
- How attention mechanisms process sequential information
- Why positional encodings are critical for transformers
- How normalization and residuals stabilize training
PEFT Trade-offs:
- LoRA is excellent for memory-constrained scenarios and multi-task deployment
- WiSE-FT excels when robustness and generalization are priorities
- The optimal $\alpha$ varies by task and distribution shift severity
Engineering Lessons:
- Proper tensor shapes and efficient operations are critical for scalability
- Modular design enables rapid experimentation
- Comprehensive testing is essential for correctness
Conclusion
This project successfully implements a complete Llama2-style transformer from scratch, including all architectural innovations (GQA, RoPE, SwiGLU) and modern training practices. The addition of LoRA and WiSE-FT demonstrates parameter-efficient fine-tuning methods that are essential for practical deployment of large language models.