
From Data to Answers: Building a Retrieval-Augmented Generation (RAG) System for Pittsburgh & CMU Knowledge
Date:
LLM, NLP, Information Retrieval, RAG
| 📄 Project Report (PDF) | 💻 GitHub Repository |
Introduction
Understanding local information—such as events, museums, sports, and campus resources—should be simple, but online data is often scattered across hundreds of pages. Our project addresses this gap by building a Retrieval-Augmented Generation (RAG) system capable of answering free-form questions about Pittsburgh and Carnegie Mellon University (CMU) with high accuracy.
The system improves access to local knowledge, supports new students and residents, and demonstrates how AI can organize large-scale heterogeneous information into clear, trustworthy answers.
 Figure 1: System Overview - RAG Pipeline Architecture
Figure 1: System Overview - RAG Pipeline Architecture
Methods
We designed a full RAG pipeline consisting of a knowledge base, retrievers, and a reader (LLM). The overall system follows the three-stage workflow:
1. Data Collection & Knowledge Base Construction
- Scraped data from official Pittsburgh & CMU websites
- Processed 77 raw data files (HTML, PDFs → JSON/TXT)
- Organized knowledge into 6 domains: Events, Museums, Music & Culture, Food, Sports, General Info
- Produced thousands of chunked text documents
2. Test Set & Evaluation Dataset
- Created a 150-question QA test set
- Measured annotation quality with IAA (Krippendorff’s $\alpha$ soft): 0.784, confirming high annotation reliability
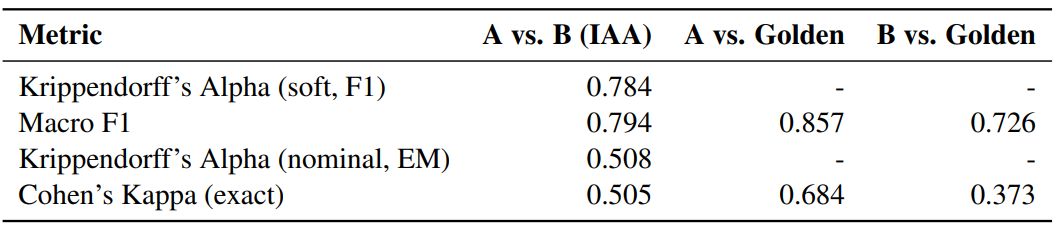 Figure 2: Inter-Annotator Agreement (IAA) and performance against the golden standard.
Figure 2: Inter-Annotator Agreement (IAA) and performance against the golden standard.
3. Model Architecture
Embedder:
all-MiniLM-L6-v2(efficient semantic encoder)multi-qa-mpnet-base-dot-v1(strong QA-optimized model)
Retrievers:
- Sparse: BM25
- Dense: FAISS cosine search
- Hybrid retrieval: normalized weighted fusion
Re-ranker:
- Cross-encoder:
BAAI/bge-reranker-v2-m3
Reader (Generator):
- Gemma-2 9B IT (4-bit quantized)
- Generates final answers using retrieved context
Results
Our experiments tested the influence of reader size, retriever type, top-k, and reranking.
Key Findings
1. RAG dramatically improves accuracy
- No-RAG F1: 28.93%
- Best RAG F1: 74.20% ✨
2. Hybrid Retrieval + Reranker achieves the best performance
- Recall: 83.11%
- EM: 46.67%
- F1: 74.20%
3. Reader size matters
- Gemma-9B ≫ Gemma-2B in accuracy, completeness, and reasoning
4. Top-K matters
- k = 10 gives best F1 (more context)
- k = 5 sometimes gives better EM (more precise)
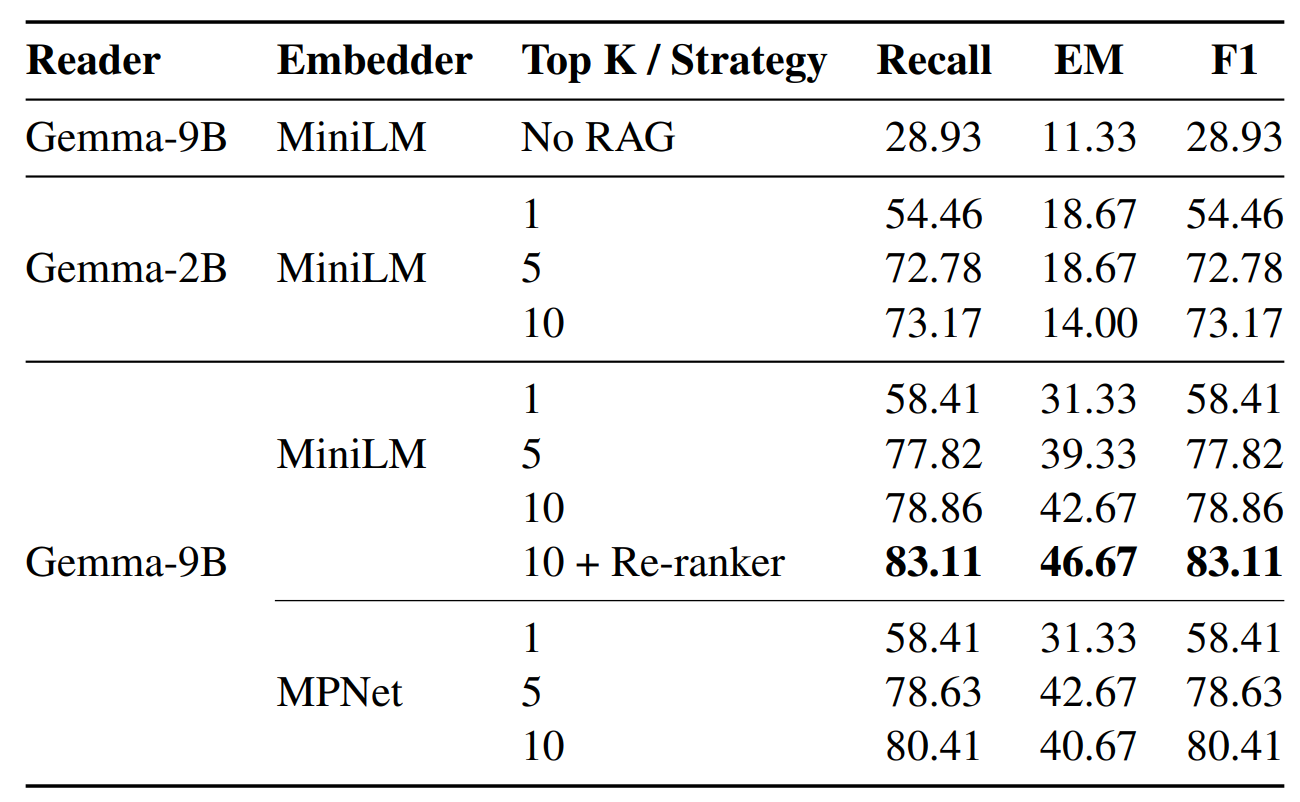 Figure 3: Performance Comparison Across Different Configurations
Figure 3: Performance Comparison Across Different Configurations
Overall, combining sparse & dense signals, then reranking, leads to the most reliable answers.
Discussion
Our analysis highlights several insights about real-world RAG behavior:
- RAG is most helpful for time-sensitive or niche information, such as events, schedules, or location-specific facts
- Pure LLMs cannot track local or updated knowledge, while retrieval ensures factual grounding
- Sparse retrieval surprisingly outperforms dense retrieval alone, due to keyword-heavy city/event information
- Hybrid + reranker provides a strong balance between precision and coverage
Conclusion
We successfully built a practical, robust RAG system that improves access to localized Pittsburgh and CMU knowledge. Through systematic evaluation, we show that combining hybrid retrieval, strong readers, and cross-encoder reranking yields the best performance.